How Bad Can It Git?
Characterizing Secret Leakage in Public GitHub Repositories
GitHub has been a fantastic tool for the development of free and open-source software.
However, there is a major security risk that happens when developers leak authentication secrets within their public repositories, often inadvertantly.
Our research team focused on demonstrating the first large-scale attack on secret leakage on GitHub.
Our hope is that our work will raise awareness to the issue and influence platforms to implement better security measures.
# Overview
The GitHub Secret Leakage Measurement is a research project that I came up with during a class on software security at NC State University.
After presenting the initial prototype in the class, my professor, Dr. Bradley Reaves, approached me and asked to continue developing it as a research project.
Along with Dr. Reaves, I worked with my partner Matt McNiece to continue work on this project.
# Abstract
GitHub and similar platforms have made public
collaborative development of software commonplace. However, a
problem arises when this public code must manage authentication
secrets, such as API keys or cryptographic secrets. These secrets
must be kept private for security, yet common development
practices like adding these secrets to code make accidental leakage
frequent. In this paper, we present the first large-scale and
longitudinal analysis of secret leakage on GitHub. We examine
billions of files collected using two complementary approaches: a
nearly six-month scan of real-time public GitHub commits and
a public snapshot covering 13% of open-source repositories. We
focus on private key files and 11 high-impact platforms with
distinctive API key formats. This focus allows us to develop
conservative detection techniques that we manually and automatically
evaluate to ensure accurate results. We find that not only
is secret leakage pervasive — affecting over 100,000 repositories
—but that thousands of new, unique secrets are leaked every day.
We also use our data to explore possible root causes of leakage
and to evaluate potential mitigation strategies. This work shows
that secret leakage on public repository platforms is rampant
and far from a solved problem, placing developers and services
at persistent risk of compromise and abuse.
# Contributions
Our work makes the following contributions:
* **We perform the first large-scale systematic study
across billions of files that measures the prevalence
of secret leakage on GitHub by extracting and validating
hundreds of thousands of potential secrets.**
We also evaluate the time-to-discovery, the rate and
timing of removal, and the prevalence of co-located
secrets. Among other findings, we find thousands of
new keys are leaked daily and that the majority of
leaked secrets remain available for weeks or longer.
* **We demonstrate and evaluate two approaches to
detecting secrets on GitHub.** We extensively validate
the discovery coverage and rejection rates of invalid
secrets, including through an extensive manual review.
* **We further explore GitHub data and metadata
to examine potential root causes.** We find that
committing cryptographic key files and API keys
embedded directly in code are the main causes of
leakage. We also evaluate the role of development
activity, developer experience, and the practice of
storing personal configuration files in repositories (e.g.,
“dotfiles”).
* **We discuss the effectiveness of potentially mitigating practices**,
including automatic leakage detectors,
requiring multiple secret values, and rate limiting
queries on GitHub. Our data indicates these techniques
all fail to limit systemic large-scale secret exposure.
# Solution
We built a multi-stage pipeline for scanning for and analyzing potential secrets from GitHub.
Our infrastructure was composed of Python software and a MongoDB instance.
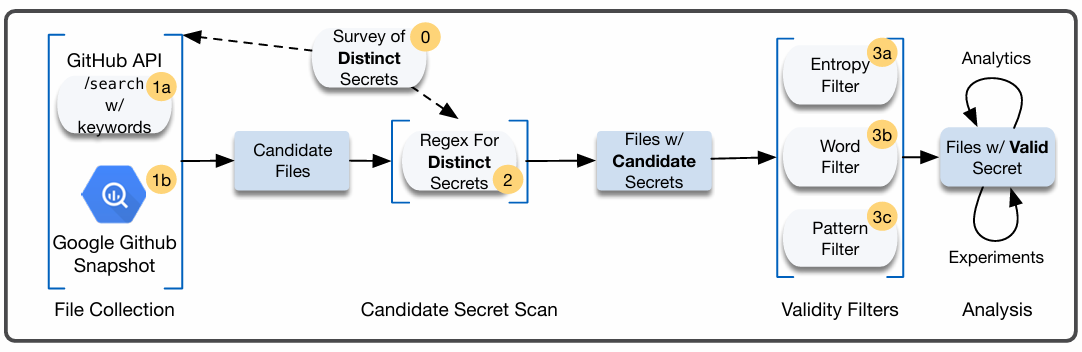
Our secret collection methodology involves various phases to identify secrets with high confidence
High-level summaries of each stage of our pipeline are below:
0. We began by surveying a wide set of common APIs that have risk of high-impact if access were compromised.
From this, we were able to identify that many APIs distributed secrets with a unique and identifiable format.
For example, all Amazon AWS Access Key ID values start with the string `AKIA`.
1. Next, we scanned multiple resources for these secrets.
1. Our primary resource was GitHub's Search API, which is used for searching code on their platform.
We identified that this API allowed near real-time searches of recent commits published to GitHub.
We were able to craft specialized queries to search for the identifiable secrets we had previously identified.
This resource essentially gave us live search results from actively developed repositories, which means that API keys were likely valid.
2. Our second resource was a Google BigQuery snapshot of GitHub open-source licenses repositories.
This was a queryably weekly snapshot that we were able to search with a limited regular expression feature set.
This provided highly flexible and powerful search approach compared to the API.
However, since the resource was a snapshot, the repositories were not guaranteed to be actively developed and so the API keys were less likely valid.
2. The scanning step provided us with a large dataset of millions of potential secrets.
Due to the limitations of the search functionality, some of the detected secrets may have been false positives.
Therefore, we further scanned these secrets offline using regular expressions to ensure higher accuracy and extract the secrets themselves.
We called the successful outputs of this phase "candidate secrets".
3. After obtaining our filtered list of candidate secrets, we now wanted to ensure that the secrets were "valid".
For ethical reasons, we would not attempt to use the secrets, and so we built a set of validity filters that would give us high confidence of validity.
As an example, we built an entropy filter that would ensure that the secrets exhibited a high degree of randomness.
Once we had our final set of valid secrets, we were able to perform data analysis.
# Analysis
Below, I have highlighted some of our select findings from the analysis:
* Over a period of 6 months, our GitHub Search API approach identified 4,394,476 files with secrets, representing 681,784 repositories.
From these, we identified a total of 133,934 unique valid secrets.
* The median time-to-discovery of a secret from commit push to our system identifying it was 20 seconds, showing that our system worked in near real-time.
* Within GitHub's API rate limits with a single API key, we were able to achieve 99% of coverage of all commits on GitHub.
* The most commonly leaked secrets were Google API secrets and RSA Private Keys.
* For "mulit-factor" authentication schemes (e.g. for OAuth, you often need a Client ID and a secret), we found that that all required values were leaked together 80% of the time.
* 19% of identified secrets were removed from the repository within 2 weeks of leakage, mostly within the first 24 hours
* We were able to compromise secrets of numerous high value targets, including AWS credentials for a major website relied upon by millions of college applicants in the United States, and AWS credentials for the website of a major government agency in a Western European country.
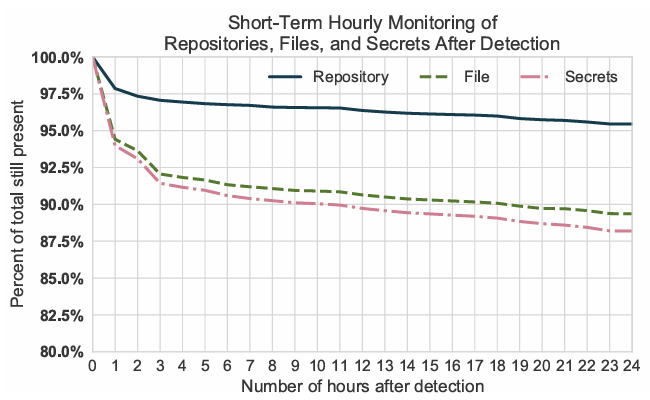
Many secrets are removed in the first few hours after being committed, but the majority remain
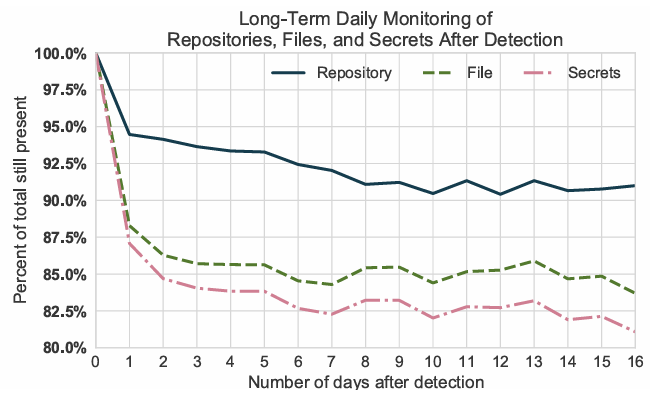
Secrets that still exist on GitHub for a day after commit tend to stay on GitHub indefinitely
# Publication
I was the primary author of our paper, "How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories".
Our paper was accepted for publication by the Network and Distributed Systems Security (NDSS) conference, one of the top-tier academic security conferences.
I presented our work at the NDSS Symposium in San Diego, California in Feburary 2019.

Michael presenting at NDSS 2019
# Impacts
One of the goals of our paper was to draw attention to the problem and pressure platforms such as GitHub to implement measures on their site to prevent secret leakage.
I was very pleased to see that after the publication of our paper, GitHub announced a new feature to implement secret scanning within repositories.
In 2024, GitHub also enabled secret scanning on push by default.
This is a fantastic feature and I am very glad to know that my work has led to such important changes.